
Building on my previous post about text processing in python which covered singular word analysis from a text summary. This post explains on how to identify 2-words & 3-words phrases from a webpage, specifically filtering the large text corpus into bigrams and trigrams using the collocations package. I chose to analyse the text from wikipedia page about the song “Hope” by The Chainsmokers, one of the most played soundtrack on Spotify which I came across recently.
Part I: Web Scraping
First, specify the web page url to perform text processing.
The urllib.request module will help us to crawl the web page, retrieving several elements such as the HTML tags, CSS, JavaScript and the web content.
import urllib.request
response = urllib.request.urlopen('https://en.wikipedia.org/wiki/Hope_(The_Chainsmokers_song)')
html = response.read()
print(html)
We will use Beautiful Soup which is a Python library for pulling data out of HTML and XML files. BeautifulSoup provides a simple way to find text content (i.e. non-HTML) from the HTML:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html.parser')
text = soup.find_all(text = True)
print(text)
However, the text found are likely to contain a few items that we do not want to be included in our text preprocessing exercise. Curate a list of unwanted items and store them as blacklist.
output = ''
blacklist = [
'[document]',
'noscript',
'header',
'html',
'meta',
'head',
'input',
'script',
'style',
# there may be more elements you don't want, such as "blockquote", etc.
]
for t in text:
if t.parent.name not in blacklist:
output += '{} '.format(t)
print(output)
Part II: Text Processing
First, download the Python Natural language toolkit (NLTK) library:
import nltk
nltk.download()
This will show the NLTK downloader to choose what packages need to be installed. I downloaded All Collections for this exercise.
Next, we need to convert all the output text to its lowercase because ‘Hope’ and ‘hope’ will be read as 2 different words.
# convert output text to lowercase
output_lower = output.lower()
Now we have a list of lowercase text crawled from the web page, let’s convert the output_lower into word tokens.
from nltk.tokenize import word_tokenize
word_tokens = word_tokenize(output_lower)
Next, to normalize the tokenized words, we need to remove punctuation and the empty strings '' from word_tokens:
from string import punctuation
word_tokens = [''.join(c for c in s if c not in punctuation) for s in word_tokens]
# remove empty strings
word_tokens = [s for s in word_tokens if s]
Part III: Collocations
Collocations are expressions consisting of two or more words that correspond to some conventional way of saying things. Collocations include noun phrases like romantic love and weapons of mass destruction, phrasal verbs like to make up, and other stock phrases like the rich and powerful.
Collocations are important for a number of applications: natural language generation (to make sure that the output sounds natural and mistakes like idealized love or to take a decision are avoided), computational lexicography (to automatically identify the important collocations to be listed in a dictionary entry), parsing (so that preference can be given to parses with natural collocations), and corpus linguistic research.
Now, let’s add the collocations package from the nltk library. The collocations package provides collocation finders which by default consider all ngrams in a text as candidate collocations:
bigrams = nltk.collocations.BigramAssocMeasures()
trigrams = nltk.collocations.TrigramAssocMeasures()
bigramFinder = nltk.collocations.BigramCollocationFinder.from_words(word_tokens)
trigramFinder = nltk.collocations.TrigramCollocationFinder.from_words(word_tokens)
import pandas as pd
#bigrams
bigram_freq = bigramFinder.ngram_fd.items()
bigramFreqTable = pd.DataFrame(list(bigram_freq), columns=['bigram','freq']).sort_values(by='freq', ascending=False)
#trigrams
trigram_freq = trigramFinder.ngram_fd.items()
trigramFreqTable = pd.DataFrame(list(trigram_freq), columns=['trigram','freq']).sort_values(by='freq', ascending=False)
All the ngrams in a text are often too many to be useful when finding collocations. It is generally useful to remove some stopwords or punctuation, and to require a minimum frequency for candidate collocations.
#get english stopwords
en_stopwords = set(stopwords.words('english'))
#function to filter for ADJ/NN bigrams
def rightTypes(ngram):
if '-pron-' in ngram or 't' in ngram:
return False
for word in ngram:
if word in en_stopwords or word.isspace():
return False
acceptable_types = ('JJ', 'JJR', 'JJS', 'NN', 'NNS', 'NNP', 'NNPS')
second_type = ('NN', 'NNS', 'NNP', 'NNPS')
tags = nltk.pos_tag(ngram)
if tags[0][1] in acceptable_types and tags[1][1] in second_type:
return True
else:
return False
#filter bigrams
filtered_bi = bigramFreqTable[bigramFreqTable.bigram.map(lambda x: rightTypes(x))]
The dataframe output of the filtered_bi will look like this:
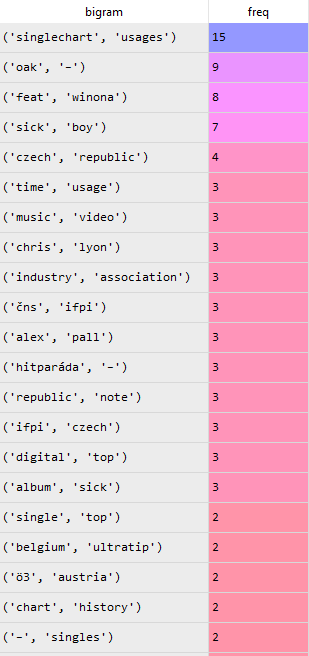
Now, let’s try to filter for trigrams:
#function to filter for trigrams
def rightTypesTri(ngram):
if '-pron-' in ngram or 't' in ngram:
return False
for word in ngram:
if word in en_stopwords or word.isspace():
return False
first_type = ('JJ', 'JJR', 'JJS', 'NN', 'NNS', 'NNP', 'NNPS')
third_type = ('JJ', 'JJR', 'JJS', 'NN', 'NNS', 'NNP', 'NNPS')
tags = nltk.pos_tag(ngram)
if tags[0][1] in first_type and tags[2][1] in third_type:
return True
else:
return False
#filter trigrams
filtered_tri = trigramFreqTable[trigramFreqTable.trigram.map(lambda x: rightTypesTri(x))]
The dataframe output of the filtered_tri will look like this:
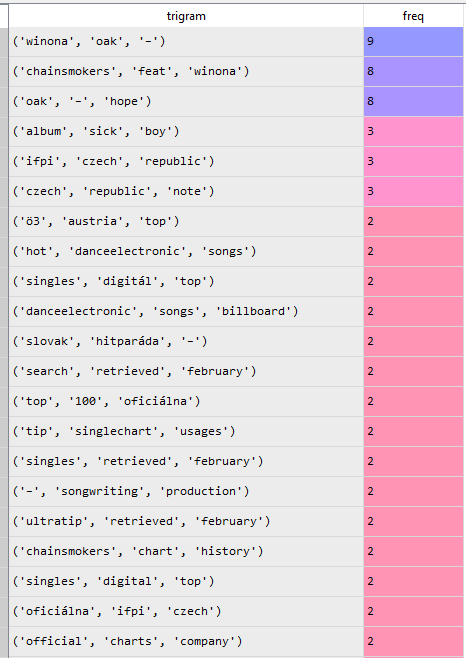
Conclusion
From the results of the filtered bigram and trigram, we can roughly draw a few insights:
- The song “Hope” is a collaboration between The Chainsmokers and Winona Oak.
- It is a popular dance electronic song which had charted the billboard.
- And for the fans of The Chainsmokers, you can probably easily identify that the song “Hope” is one of the singles from the Chainsmokers’ second studio album called
Sick Boy.
Interesting, isn’t it?