
Retrieving semi & unstructured data from the webpage to conduct Natural Language Processing (NLP) is one of the most common tasks in many text/sentiments analysis project. In this post, I covered the basics of web scraping, text processing and basic visualisation using Python, which includes 1) Web Crawling, 2) Tokenisation, 3) Text Normalisation, 4) Lemmatisation and 5) basic frequency distribution & word cloud visualisation. I chose to analyse a text summary of Chapter XXI in ‘The Little Prince’ novel (as one of my favourite books) for it holds a deep & special meaning about relationships in life.
Part I: Web Scraping
First, specify the web page url which you are interested to perform text processing.
The urllib.request module will help us to crawl the web page, retrieving several elements such as the HTML tags, CSS, JavaScript and the web content.
import urllib.request
response = urllib.request.urlopen('https://www.sparknotes.com/lit/littleprince/section7/')
html = response.read()
print(html)
We will use Beautiful Soup which is a Python library for pulling data out of HTML and XML files. BeautifulSoup provides a simple way to find text content (i.e. non-HTML) from the HTML:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html.parser')
text = soup.find_all(text = True)
print(text)
However, the text found are likely to contain a few items that we do not want to be included in our text preprocessing exercise. Curate a list of unwanted items and store them as blacklist.
output = ''
blacklist = [
'[document]',
'noscript',
'header',
'html',
'meta',
'head',
'input',
'script',
'style',
# there may be more elements you don't want, such as "blockquote", etc.
]
for t in text:
if t.parent.name not in blacklist:
output += '{} '.format(t)
print(output)
Part II: Text Processing
The data preprocessing steps for this exercise includes the following:
- Tokenization — separating text/string data into units (paragraphs, sentences or words)
- Text Normalization — converting all letters to lower or upper case, removing unnecessary punctuation, empty strings
- Removing stop words — frequent words such as ”the”, ”is”, etc. that do not have specific semantic
- Lemmatization — reduce words with different forms like ‘loves’, ‘loving’, ‘lovely’ to a common base form or root word ‘love’.
First, download the Python Natural language toolkit (NLTK) library:
import nltk
nltk.download()
This will show the NLTK downloader to choose what packages need to be installed. I downloaded All Collections for this exercise.
Next, we need to convert all the output text to its lowercase because ‘Rose’ and ‘rose’ will be read as 2 different words.
# convert output text to lowercase
output_lower = output.lower()
Tokenization
Now we have a list of lowercase text crawled from the web page, let’s convert the output_lower into word tokens. Word tokenizing splits text into individual words and gives structure to previously unstructured text. eg: “to establish ties.” as '"','to','establish','ties','.','"'
from nltk.tokenize import word_tokenize
word_tokens = word_tokenize(output_lower)
Text Normalization
Next, to normalize the tokenized words, we need to remove punctuation and the empty strings '' from word_tokens:
from string import punctuation
word_tokens = [''.join(c for c in s if c not in punctuation) for s in word_tokens]
# remove empty strings
word_tokens = [s for s in word_tokens if s]
To further cleanup the text corpus, let’s remove the “stop words” that often do not carry important meaning.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_tokens = [w for w in word_tokens if not w in stop_words]
Lemmatization
Lemmatization — another approach to remove inflection by determining the part of speech and utilizing detailed database of the language. Unlike Stemming, lemmatization reduces the inflected words properly ensuring that the root word belongs to the language. For example, the root word of Lemmatization is called Lemma. A lemma (plural lemmas or lemmata) is the canonical form, dictionary form, or citation form of a set of words.
from nltk.stem import WordNetLemmatizer
# init the wordnet lemmatizer
lmtzr = WordNetLemmatizer()
lemm_tokens = [lmtzr.lemmatize(x) for x in filtered_tokens]
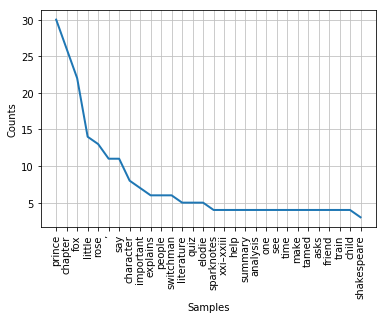
For a sensing on the top 30 words used in the text, we can visualize the lemmatized word tokens in a frequency distribution graph. nltk offers a function FreqDist() to count word frequency:
freq = nltk.FreqDist(lemm_tokens)
for key,val in freq.items():
print(str(key) + ':' + str(val))
freq.plot(30, cumulative=False)
The output will look like this:
Creation of Word Cloud
Another helpful visualization tool would be the wordcloud package which helps to create word clouds with sizes proportional to their frequency in the text.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wc = WordCloud().generate_from_frequencies(freq)
plt.imshow(wc)
plt.axis("off")
plt.show()
